



فناوری Biren به طور رسمی اولین پردازندههای گرافیکی خود را که عمدتاً برای هوش مصنوعی (AI) و محاسبات با عملکرد بالا (HPC) طراحی شدهاند، معرفی کرده است. به گفته این شرکت، پردازنده گرافیکی رده بالای BR100 می تواند تراشه های A100 و حتی H100 انویدیا را در بارهای کاری خاص به چالش بکشد، اما پیچیدگی آن با پردازنده گرافیکی محاسباتی H100 انویدیا قابل مقایسه است. مقاله پردازندههای گرافیکی چینی Biren با 77 میلیارد ترانزیستور را با کمک فروشگاه رایان مارکت در حال ارائه هستیم.
در لپ تاپ استوک خانواده اولیه پردازندههای گرافیکی محاسباتی Biren شامل دو تراشه است. BR100 تا 256 FP32 TFLOPS یا 2 INT8 PetaFLOPS را وعده می دهد، در حالی که BR104 تا 128 FP32 TFLOPS یا 1 عملکرد INT8 PetaFLOPS رتبه بندی شده است.
پردازندههای گرافیکی چینی Biren با 77 میلیارد ترانزیستور
رده بالای BR100 با 64 گیگابایت حافظه HBM2E با رابط 4096 بیتی (1.64 ترابایت بر ثانیه)، در حالی که BR104 میان رده با 32 گیگابایت حافظه HBM2E با رابط 2048 بیتی (819 گیگابایت بر ثانیه) عرضه می شود.
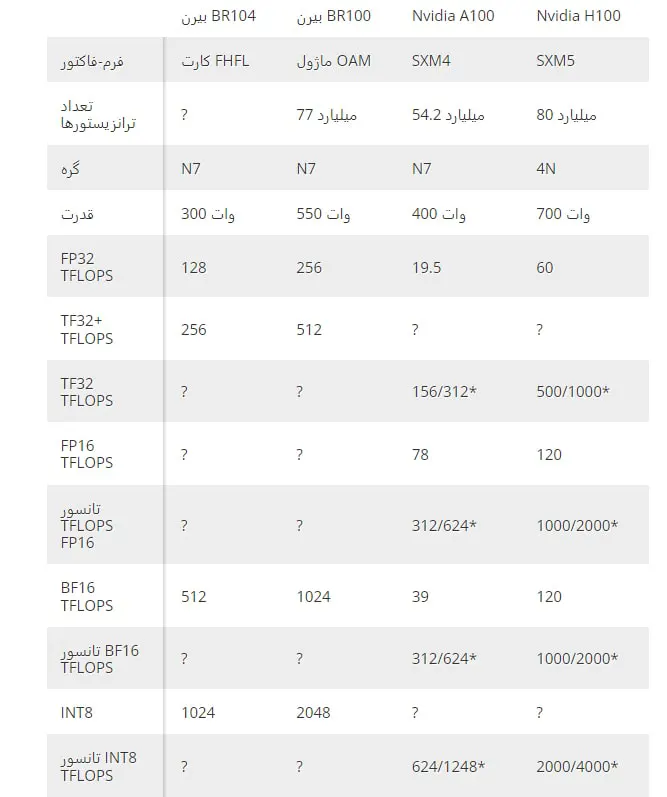
هر دو تراشه از فرمتهای داده INT8، FP16، BF16، FP32 و TF32+ پشتیبانی میکنند، بنابراین ما در مورد فرمتهای ابررایانه (مثلا FP64) صحبت نمیکنیم، حتی اگر Biren میگوید که فرمت TF32+ آن دقت دادهای بالاتر از TF32 سنتی ارائه میدهد. در همین حال، BR100 و BR104 اعداد عملکرد نسبتاً قابل توجهی را ارائه می دهند. در واقع، اگر این شرکت عملکردهای خاص GPU (واحدهای بافت، رندرهای پشتی و غیره) را در پردازندههای گرافیکی محاسباتی خود گنجانده بود و درایورهای مناسبی را طراحی میکرد، این تراشهها پردازندههای گرافیکی نسبتاً باورنکردنی بودند (حداقل BR104، که احتمالاً یک پیکربندی تک تراشه).
علاوه بر قابلیتهای محاسباتی، پردازندههای گرافیکی Biren میتوانند از کدگذاری و رمزگشایی ویدیوی H.264 نیز پشتیبانی کنند.
پردازنده Biren با 77 میلیارد ترانزیستور
پردازنده گرافیکی BR100 بایرن در فرم فاکتور OAM در دسترس خواهد بود و تا 550 وات برق مصرف می کند. این تراشه از فناوری اختصاصی BLink 8 طرفه این شرکت پشتیبانی می کند که امکان نصب حداکثر هشت پردازنده گرافیکی BR100 را در هر سیستم فراهم می کند. در مقابل، BR104 300 واتی با فرم فاکتور کارت PCIe با پهنای دوگانه FHFL عرضه می شود و از پیکربندی چند GPU تا 3 طرفه پشتیبانی می کند. EETrend (از طریق VideoCardz) گزارش می دهد که هر دو تراشه از یک رابط PCIe 5.0 x16 با پروتکل CXL برای شتاب دهنده ها در بالا استفاده می کنند.
Biren می گوید که هر دو تراشه آن با استفاده از فرآیند ساخت کلاس 7 نانومتری TSMC ساخته شده اند (بدون توضیح اینکه آیا از N7، N7+ یا N7P استفاده می کند). BR100 بزرگتر دارای 77 میلیارد ترانزیستور است که با Nvidia A100 که همچنین با استفاده از یکی از گره های N7 TSMC ساخته شده است، از 54.2 میلیارد ترانزیستور بیشتر است. این شرکت همچنین میگوید که برای غلبه بر محدودیتهای اعمالشده توسط اندازه شبکه TSMC، باید از طراحی چیپلت و فناوری CoWoS 2.5D کارخانه ریختهگری استفاده میکرد، که کاملاً منطقی است زیرا A100 انویدیا به اندازه یک شبکه نزدیک میشد و BR100 قرار است یکسان باشد. با توجه به تعداد ترانزیستورهای آن بزرگتر است.
با توجه به مشخصات، میتوان حدس زد که BR100 اساساً از دو BR104 استفاده میکند، اگرچه توسعهدهنده آن را به طور رسمی تأیید نکرده است.
برای تجاریسازی شتابدهنده BR100 OAM، Biren با Inspur روی یک سرور هوش مصنوعی 8 طرفه کار کرد که از سهماهه چهارم 2022 نمونهبرداری میکند. Baidu و China Mobile جزو اولین مشتریانی خواهند بود که از پردازندههای گرافیکی محاسباتی Biren استفاده میکنند.




